Apollo + Lemlist: the cold-email stack Hopkins would build today
Reason-why advertising split across two tools — sourcing precision and cadence with
reply tracking. List first, cadence second; most operators do the reverse.
Try Apollo free →
The Hopkins move, in 2026 cold email
Around 1919, Schlitz beer was near the bottom of American brewing. Same recipe as every
competitor, same price, same channel. Then Claude Hopkins wrote one campaign — the copy
that explained Schlitz sterilized every bottle in glass-enclosed rooms, filtered the water,
cultivated the yeast for a decade. Same beer the competitors brewed; the operator-test
detail printed for the consumer. Sales moved Schlitz to a tie for first place inside a year.
1919 · Schlitz
Tied #1
Bottom-half brewer to category leader inside a year — one campaign, one operator-test detail printed.
Hopkins's discipline
Per 1,000
Coupon return tracked per thousand pieces mailed. Variant isolation, not "advertising" optimization.
2026 cold email
Per template
Reply rate measured per sequence variant. Same discipline, two tools deep.
That campaign isn't an ad-history footnote. It's the discipline cold email keeps
forgetting.
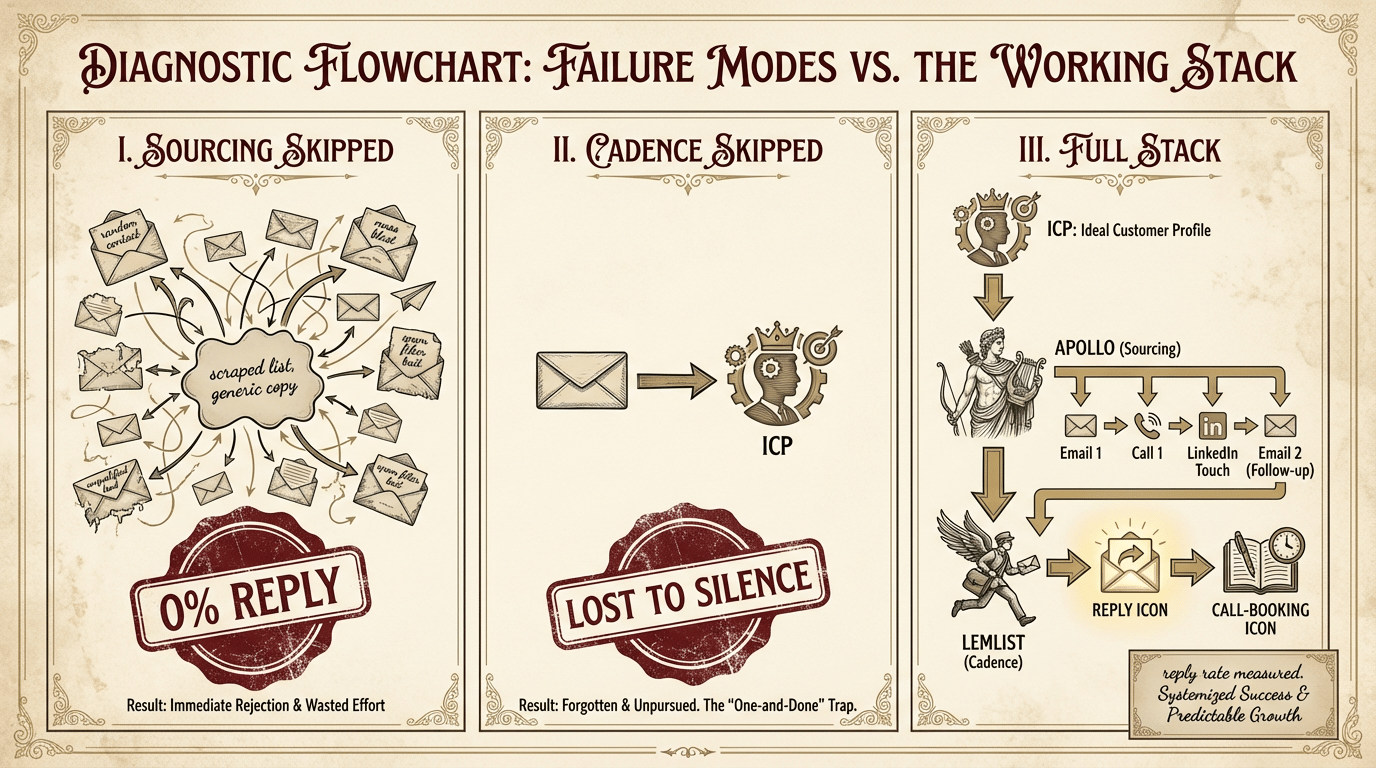
The two failure modes that kill cold email
Failure 1 · sourcing skipped
1,000 generic emails to a scraped list, 0% reply rate, conclusion that the channel is
broken. The list was the broken part — never the channel.
Failure 2 · cadence skipped
One email, no follow-up, no reply tracking. Any reply gets attributed to luck;
every silence reads as rejection. The reply rate is invisible because the system
doesn't measure.
Hopkins didn't mail to "general consumers." He mailed to specific subscriber lists with
measurable demographic profiles, tracked the coupon return per thousand, and isolated which
copy variant returned. The 2026 cold-email stack splits that exact discipline across two
tools.
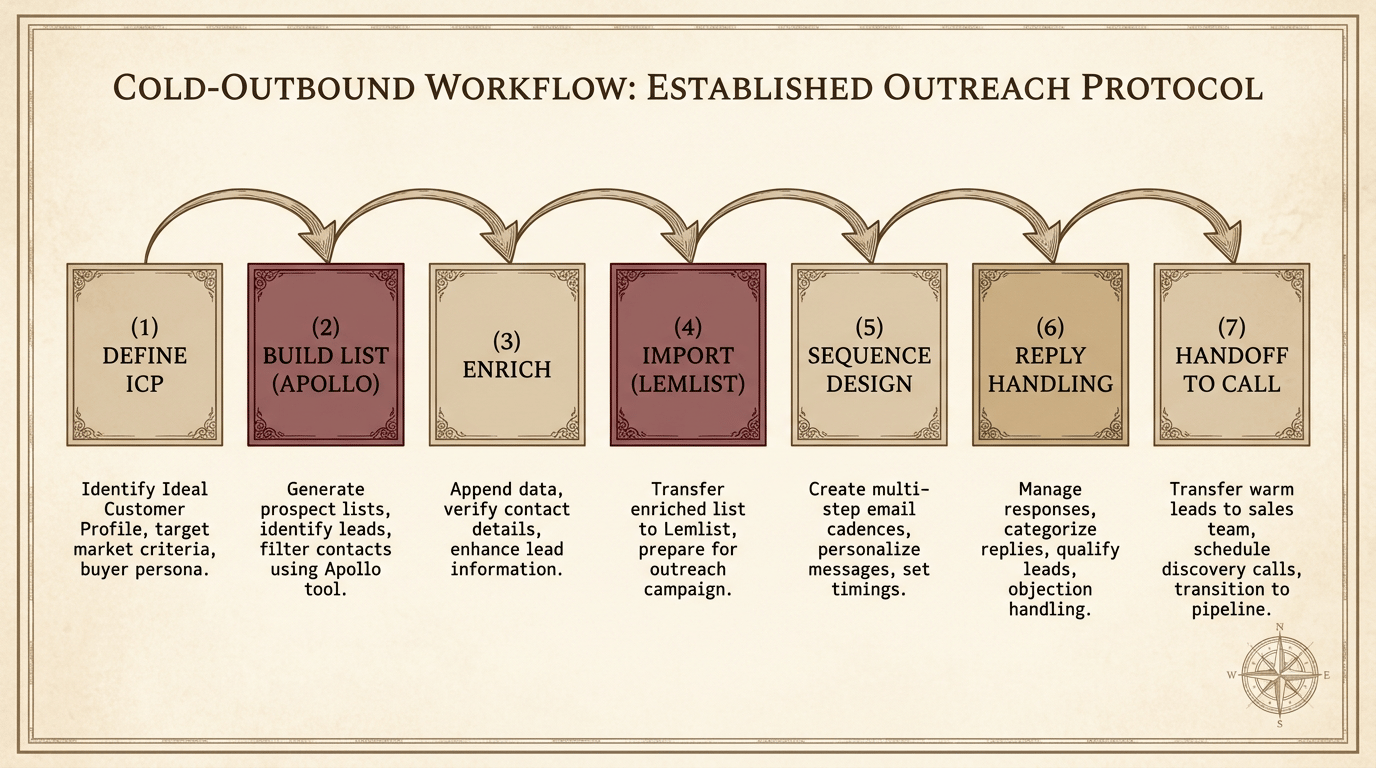
The stack, by half
Half 01
250M+ contacts database. Surgical filters: title, headcount, location, last-funded
date, tech stack, hiring signal, role change. Hopkins's circulation analysis at 2026
scale — 5 minutes for what a Lord & Thomas planner did in two weeks.
Half 02
3–7 emails over 14–21 days. Variable-level personalization — custom
images, dynamic intros, video thumbnails with the prospect's name. Reply rate measured
per template variant.
Discipline
Iterate the variant, not the program
Hopkins's "coupon returned X per thousand" → today's "this sequence returns Y%,
the variant returns Z%." Stack first, optimize second. That's the move.